
python爬虫不可不知的10个高效数据清洗方法(二)
本文接着上一篇继续学习爬虫里的数据清洗方法:
3. JSON数据清洗
网络上作为前后端分离的数据,大部分使用的是json格式的返回数据。比如下面的我们以星球大战里的人物信息的API为例。
数据URL:https://swapi.dev/api/people/
{
"count": 82,
"next": "https://swapi.dev/api/people/?page=2",
"previous": null,
"results": [
{
"name": "Luke Skywalker",
"height": "172",
"mass": "77",
"hair_color": "blond",
"skin_color": "fair",
"eye_color": "blue",
"birth_year": "19BBY",
"gender": "male",
"homeworld": "https://swapi.dev/api/planets/1/",
"films": [
"https://swapi.dev/api/films/1/",
"https://swapi.dev/api/films/2/",
"https://swapi.dev/api/films/3/",
"https://swapi.dev/api/films/6/"
],
"species": [],
"vehicles": [
"https://swapi.dev/api/vehicles/14/",
"https://swapi.dev/api/vehicles/30/"
],
"starships": [
"https://swapi.dev/api/starships/12/",
"https://swapi.dev/api/starships/22/"
],
"created": "2014-12-09T13:50:51.644000Z",
"edited": "2014-12-20T21:17:56.891000Z",
"url": "https://swapi.dev/api/people/1/"
},
{
"name": "C-3PO",
"height": "167",
"mass": "75",
"hair_color": "n/a",
"skin_color": "gold",
"eye_color": "yellow",
"birth_year": "112BBY",
"gender": "n/a",
"homeworld": "https://swapi.dev/api/planets/1/",
"films": [
"https://swapi.dev/api/films/1/",
"https://swapi.dev/api/films/2/",
"https://swapi.dev/api/films/3/",
"https://swapi.dev/api/films/4/",
"https://swapi.dev/api/films/5/",
"https://swapi.dev/api/films/6/"
],
"species": [
"https://swapi.dev/api/species/2/"
],
"vehicles": [],
"starships": [],
"created": "2014-12-10T15:10:51.357000Z",
"edited": "2014-12-20T21:17:50.309000Z",
"url": "https://swapi.dev/api/people/2/"
}
]
}Code language: JavaScript (javascript)解析上面的这种数据很简单的啦,使用response.json() 就可以实现。
url="https://swapi.dev/api/people/"
response = requests.get(url,verify=False)
json_data = response.json()
print(json_data)Code language: Python (python)返回的dict格式的数据,需要获取具体数据,用json_data[‘results’]就好了。
如果json数据里面有中文或者其他非英文字符造成乱码,可以解析json之前先做编程转换。
url="https://swapi.dev/api/people/"
response = requests.get(url,verify=False)
response.encoding = 'utf8'
json_data = response.json()
print(json_data)Code language: PHP (php)4. 数据导入非结构化的数据库 MongoDB,数据去重
在上面的星球大战的例子中,获取到的json数据,里面有个字段films,类型为list,如果这个数据存储到MYSQL关系型数据库,是不便于检索数据的。
而文档型数据库MongoDB就天生专门用于处理json格式的数据。
首先需要安装MongoDB数据库,然后使用pip安装
pip install pymongo把爬取到的数据插入的MongoDB数据库
import pymongo
url="https://swapi.dev/api/people/"
response = requests.get(url,verify=False)
json_data = response.json()
user='your mongodb user'
password='your mongodb password'
host='your mongodb ip'
port='your mongodb port'
connect_uri = f'mongodb://{user}:{password}@{host}:{port}'
client = pymongo.MongoClient(connect_uri)
db = client['db_spider'] # database name can define by youself
collection = db['wars_star'] # collection name can define by youself
collection.insert_many(json_data['results'])Code language: Python (python)然后打开MongoDB数据库管理软件 ,比如Robot3T,连接到你自己的MongoDB数据库。
在里面就可以看到你刚刚爬到的数据啦。
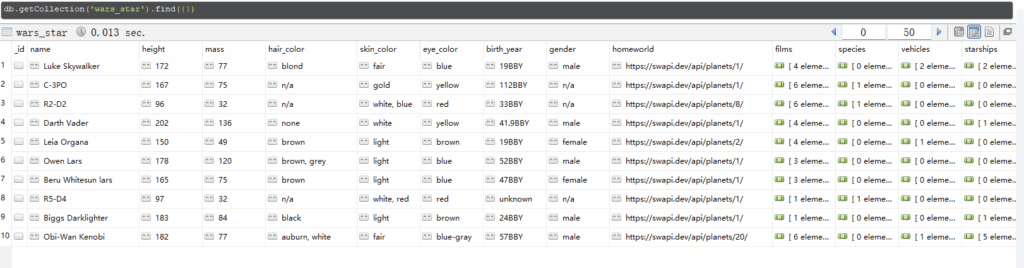
是不是很方便,很简单呢?
比mysql这种数据库剩下了建表操作,插入的时候也不用写繁琐的插入语句,尤其是字段特别多的时候,写那些mysql插入数据语句的场景,就让人抓狂了。
而用MongoDB查询json类型的文档数据,也很方便。
举例子,比如获取name字段里么包含“Le”字符的所有数据,那么语句是这样的:
db.getCollection('wars_star').find({'name':/Le/})
Code language: JavaScript (javascript)
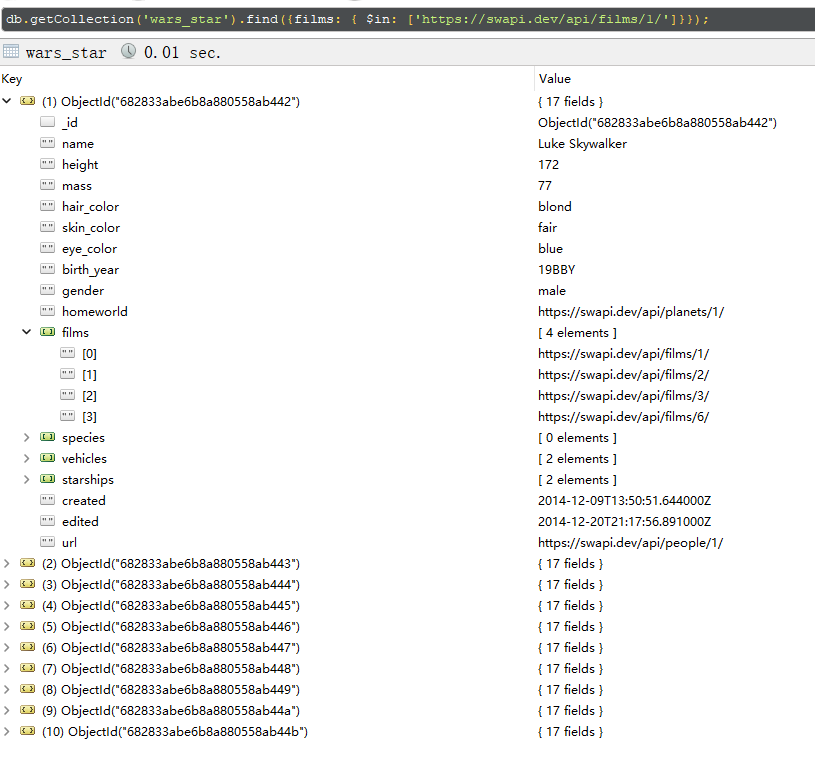
films是array类型的字段,如果我要查询films里面包含https://swapi.dev/api/films/1/的所有人的记录,那么查询语句如下:
db.getCollection('wars_star').find({films: { $in: ['https://swapi.dev/api/films/1/']}});Code language: JavaScript (javascript)Robot3T返回的数据如下:
假如我们又重复的数据,不想重复插入的Mongodb数据库中,可以在Mongodb的文档中创建一个唯一索引,
比如上面的例子中,我们以name作为唯一的字段进行去重:
先创建唯一索引:
db.wars_star.createIndex(
{ name: 1 },
{ unique: true }
);Code language: JavaScript (javascript)然后插入的时候insert_many需要假如参数ordered=False,这样才可以在批量插入的时候遇到重复的数据跳过。
如果没有设置那个参数ordered为False时,只要插入的数量里面有和Mongodb里的name一样的,就会因为重复报错而终止其余的数据插入动作。
connect_uri = f'mongodb://{user}:{password}@{host}:{port}'
client = pymongo.MongoClient(connect_uri)
db = client['db_spider']
collection = db['wars_star']
collection.insert_many(json_data['results'],ordered=False)Code language: Python (python)5. JavaScript 原始对象数据(JSONP格式)
在上面的例子,返回的json数据是经过javascript JSON.stringify()格式化的数据。但,有一些原生的JSONP数据,其返回的是JavaScript原生数据,
比如中国最大的股票基金网站东方财富网,其股票基金数据返回的数据是这样的:
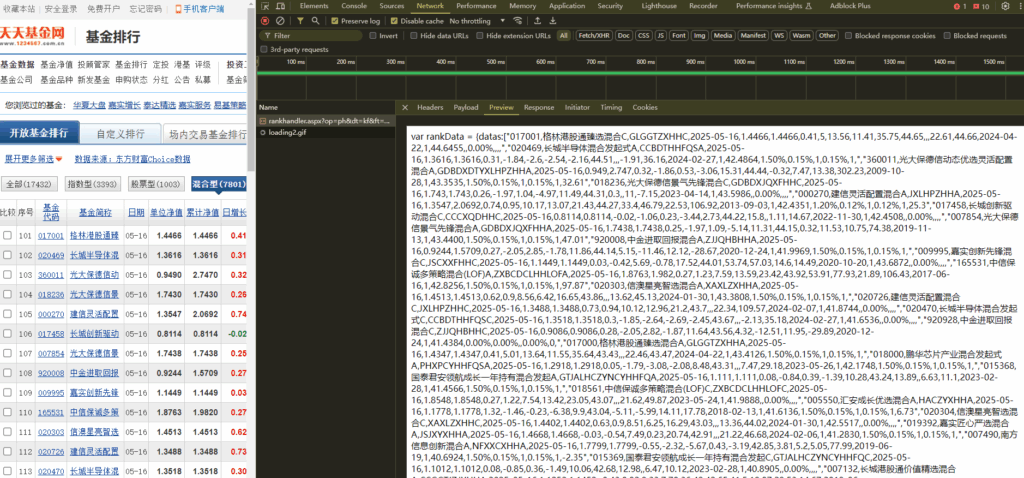
返回的数据格式:
var rankData = {datas: [
"017001,格林港股通臻选混合C,GLGGTZXHHC,2025-05-16,1.4466,1.4466,0.41,5,13.56,11.41,35.75,44.65,,,22.61,44.66,2024-04-22,1,44.6455,,0.00%,,,,",
"020469,长城半导体混合发起式A,CCBDTHHFQSA,2025-05-16,1.3616,1.3616,0.31,-1.84,-2.6,-2.54,-2.16,44.51,,,-1.91,36.16,2024-02-27,1,42.4864,1.50%,0.15%,1,0.15%,1,",
"360011,光大保德信动态优选灵活配置混合A,GDBDXDTYXLHPZHHA,2025-05-16,0.949,2.747,0.32,-1.86,0.53,-3.06,15.31,44.44,-0.32,7.47,13.38,302.23,2009-10-28,1,43.3535,1.50%,0.15%,1,0.15%,1,32.61",
"501208,中欧创新未来混合(LOF),ZOCXWLHHLOF,2025-05-16,0.9825,0.9825,-0.5,0.46,6.4,-0.57,15.64,40.22,12.12,12.79,15.56,-1.75,2020-10-09,1,39.8178,,0.00%,,,,",
"008998,同泰竞争优势混合C,TTJZYSHHC,2025-05-16,1.0334,1.0334,2.91,2.46,13.69,6.56,20.33,40.1,16.24,9.6,30.02,3.34,2020-04-27,1,37.1466,,0.00%,,,,3.43",
"017461,长城久鑫混合C,CCJXHHC,2025-05-16,1.8615,1.8615,2.06,1.73,16.19,10.01,41.84,40,12.91,,40.48,16.38,2022-11-30,1,40.3000,,0.00%,,,,"
],allRecords: 7801,pageIndex: 3,pageNum: 50,allPages: 157,allNum: 17432,zs_count: 3393,gp_count: 1003,hh_count: 7801,zq_count: 4153,qdii_count: 206,fof_count: 874
};Code language: JavaScript (javascript)数据是原生的JavaScript的格式,和json是有区别,首先数据是一个变量,可以使用查询获取中间部分的数据:
response = requests.request("GET", url, headers=headers, data=payload)
data = response.text
js_format_data = data[data.find('=') + 2: data.rfind(';')]Code language: Python (python)通过上面的语句,可以获取{}里面的数据。
当时,获取的数据并不是json格式,字段名称没有使用引号。
其次,datas里面的array数据,有一些是空的数据,但格式是,,,,, 并不是用的null,或者None,这样的数据。
如果直接使用json.loads(js_format_data),会直接报错。
此时需要使用一个第三方的库–demjson,用于解析JavaScript原始对象。
安装:
pip install demjsonCode language: Bash (bash)解析代码:
def parse(js_format_data):
rawdata = demjson.decode(js_format_data)
rank_list = []
for i in rawdata['datas']:
rank_list.append(i.split(','))
return rank_listCode language: Python (python)最后返回的rank_list数据就是解析到的列表数据。
6 正则表达式re

爬虫里使用正则表达式是最原始的数据清洗方式,但也是最万能的方式。如果遇到无法提取的数据,最后都可以使用正则表达式获取。
对于爬虫工程师来说,正则表达也是一项必备的技能。
- 提取单个数据 re.search
re.search()方法扫描整个字符串,并返回第一个成功的匹配。如果匹配失败,则返回None。
比如我们要获取quaro的博主的粉丝数量。
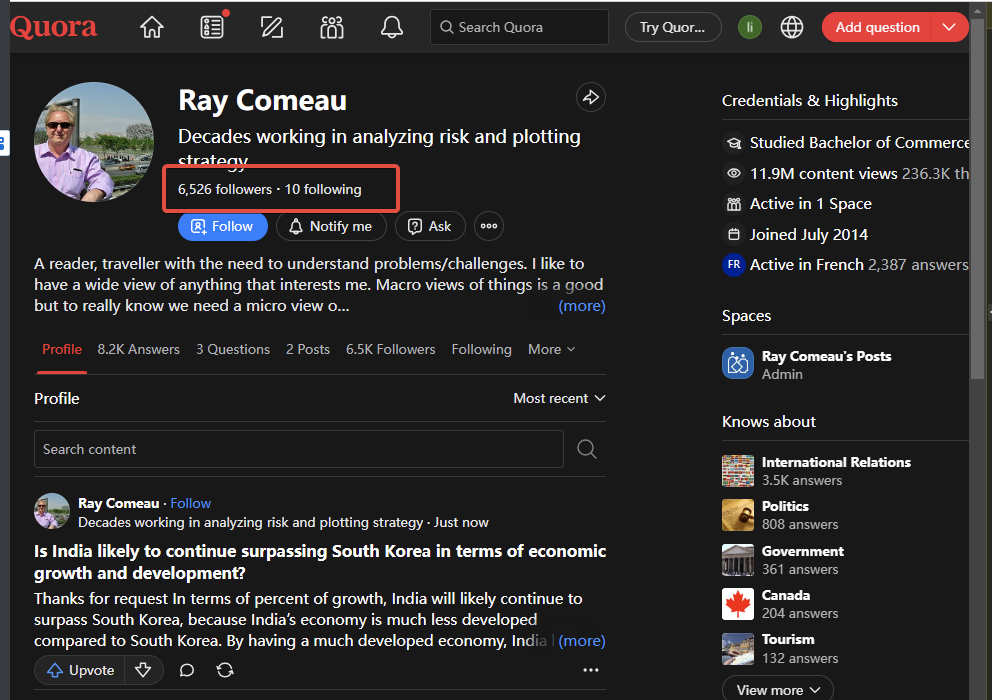
它的HTML源码如下:
<div class="q-text qu-dynamicFontSize--small qu-color--gray" style="box-sizing: border-box;">6,526 followers</div>Code language: HTML, XML (xml)因为页面里有多个div的calss是一样的。而因为页面只获取一次它的粉丝数量。所以直接使用正则表达式获取,方便省时间。
那么我们可以获取 >(.?) followers< 里面的数据,使用 .? 可以匹配任何的数据。
number = re.search('>(.*?) followers<',html).group(1)
number = int(number.repalce(',','')) # 替换,
# return int 6526Code language: Python (python)- 多个数据 re.findall
re.findall() 是正则表达式模块(re)中的一个重要函数,用于在字符串中查找所有匹配某个模式的子串,并返回一个列表
string = """Hello my Phone Number is 18767543212 and
my friend's number is 19767443218"""Code language: Python (python)如果要提取文本里面的全部电话号码,可以使用re.findall继续匹配
import re
string = """Hello my Phone Number is 18767543212 and
my friend's number is 19767443218"""
regex = '\d{11}'
all_phones = re.findall(regex, string)
print(all_phones)Code language: Python (python)输出的结果:
['18767543212', '19767443218']Code language: JSON / JSON with Comments (json)好了,学累了吧?对于爬虫中的数据清洗方式,今天我们就学到这里吧,本系列文章关注数据清洗方式,如果对数据爬取有疑惑,可以浏览 爬取HTML页面:Python爬虫教程爬取HTML页面
后面还有哦,敬请期待下一篇干货哦!